How-Tos¶
Details about tiny-dnn’s API and short examples.
construct the network model¶
There are two types of network model available: sequential and graph. A graph representation describe network as computational graph - each node of graph is layer, and each directed edge holds tensor and its gradients. Sequential representation describe network as linked list - each layer has at most one predecessor and one successor layer.
Two types of network is represented as network
sequential model¶
You can construct networks by chaining operator << from top(input) to bottom(output).
// input: 32x32x1 (1024 dimensions) output: 10
network<sequential> net;
net << convolutional_layer(32, 32, 5, 1, 6) << tanh() // 32x32in, conv5x5
<< average_pooling_layer(28, 28, 6, 2) << tanh() // 28x28in, pool2x2
<< fully_connected_layer(14 * 14 * 6, 120) << tanh()
<< fully_connected_layer(120, 10);
// input: 32x32x3 (3072 dimensions) output: 40
network<sequential> net;
net << convolutional_layer(32, 32, 5, 3, 9) << relu()
<< average_pooling_layer(28, 28, 9, 2) << relu()
<< fully_connected_layer(14 * 14 * 9, 120) << tanh()
<< fully_connected_layer(120, 40) << softmax();
If you feel these syntax a bit redundant, you can also use “shortcut” names defined in tiny_dnn.h.
using namespace tiny_dnn::layers;
net << conv(32, 32, 5, 3, 9) << relu()
<< ave_pool(28, 28, 9, 2) << relu()
<< fc(14 * 14 * 9, 120) << tanh()
<< fc(120, 40) << softmax();
If your network is simple mlp(multi-layer perceptron), you can also use make_mlp function.
auto mynet = make_mlp<tanh>({ 32 * 32, 300, 10 });
It is equivalent to:
network<sequential> mynet;
mynet << fully_connected_layer(32 * 32, 300) << tanh()
<< fully_connected_layer(300, 10) << tanh();
graph model¶
To construct network which has branch/merge in their model, you can use network<graph> class. In graph model, you should declare each “node” (layer) at first, and then connect them by operator <<. If two or more nodes are fed into 1 node, operator, can be used for this purpose.
After connecting all layers, call construct_graph function to register node connections to graph-network.
// declare nodes
layers::input in1(shape3d(3, 1, 1));
layers::input in2(shape3d(3, 1, 1));
layers::add added(2, 3);
layers::fc out(3, 2);
activation::relu r();
// connect
(in1, in2) << added;
added << out << r;
// register to graph
network<graph> net;
construct_graph(net, { &in1, &in2 }, { &out });
train the model¶
regression¶
Use network::fit function to train. Specify loss function by template parameter (mse, cross_entropy, cross_entropy_multiclass are available), and fed optimizing algorithm into first argument.
network<sequential> net;
adagrad opt;
net << layers::fc(2, 3) << activation::tanh()
<< layers::fc(3, 1) << activation::softmax();
// 2training data, each data type is 2-dimensional array
std::vector<vec_t> input_data { { 1, 0 }, { 0, 2 } };
std::vector<vec_t> desired_out { { 2 }, { 1 } };
size_t batch_size = 1;
size_t epochs = 30;
net.fit<mse>(opt, input_data, desired_out, batch_size, epochs);
If you want to do something for each epoch / minibatch (profiling, evaluating accuracy, saving networks, changing learning rate of optimizer, etc), you can register callbacks for this purpose.
// test&save for each epoch
int epoch = 0;
timer t;
nn.fit<mse>(opt, train_images, train_labels, 50, 20,
// called for each mini-batch
[&](){
t.elapsed();
t.reset();
},
// called for each epoch
[&](){
result res = nn.test(test_images, test_labels);
cout << res.num_success << "/" << res.num_total << endl;
ofstream ofs (("epoch_"+to_string(epoch++)).c_str());
ofs << nn;
});
classification¶
As with regression task, you can use network::fit function in classification. Besides, if you have labels(class-id) for each training data, network::train can be used. Difference between network::fit and network::train is how to specify the desired outputs - network::train takes label_t type, instead of vec_t.
network<sequential> net;
adagrad opt;
net << layers::fc(2, 3) << activation::tanh()
<< layers::fc(3, 4) << activation::softmax();
// input_data[0] should be classified to id:3
// input_data[1] should be classified to id:1
std::vector<vec_t> input_data { { 1, 0 }, { 0, 2 } };
std::vector<label_t> desired_out { 3, 1 };
size_t batch_size = 1;
size_t epochs = 30;
net.train<mse>(opt, input_data, desired_out, batch_size, epochs);
train graph model¶
If you train graph network, be sure to fed input/output data which has same shape to network’s input/output layers.
network<graph> net;
layers::input in1(2);
layers::input in2(2);
layers::concat concat(2, 2);
layers::fc fc(4, 2);
activation::relu r();
adagrad opt;
(in1, in2) << concat;
concat << fc << r;
construct_graph(net, { &in1, &in2 }, { &r });
// 2training data, each data type is tensor_t and shape is [2x2]
//
// 1st data for in1 2nd data for in1
// | |
// | 1st data for in2 | 2nd data for in2
// | | | |
std::vector<tensor_t> data{ { { 1, 0 }, { 3, 2 } },{ { 0, 2 }, { 1, 1 } } };
std::vector<tensor_t> out { { { 2, 5 } },{ { 3, 1 } } };
net.fit<mse>(opt, data, out, 1, 1);
without callback
...
adadelta optimizer;
// minibatch=50, epoch=20
nn.train<cross_entropy>(optimizer, train_images, train_labels, 50, 20);
with callback
...
adadelta optimizer;
// test&save for each epoch
int epoch = 0;
nn.train<cross_entropy>(optimizer, train_images, train_labels, 50, 20, [](){},
[&](){
result res = nn.test(test_images, test_labels);
cout << res.num_success << "/" << res.num_total << endl;
ofstream ofs (("epoch_"+to_string(epoch++)).c_str());
ofs << nn;
});
“freeze” layers¶
You can use layer::set_trainable to exclude a layer from updating its weights.
network<sequential> net = make_mlp({10,20,10});
net[1]->set_trainable(false); // freeze 2nd layer
use/evaluate trained model¶
predict a value¶
network<sequential> net;
// train network
vec_t in = {1.0, 2.0, 3.0};
vec_t result = net.predict(in);
double in[] = {1.0, 2.0, 3.0};
result = net.predict(in);
predict caclulates output vector for given input.
You can use vec_t, std::vector<float>, double[] and any other range as input.
We also provide predict_label and predict_max_value for classification task.
void predict_mnist(network<sequential>& net, const vec_t& in) {
std::cout << "result:" << net.predict_label(in) << std::endl;
std::cout << "similarity:" << net.predict_max_value(in) << std::endl;
}
evaluate accuracy¶
calculate the loss¶
std::vector<vec_t> test_data;
std::vector<vec_t> test_target_values;
network<sequential> net;
// the lower, the better
double loss = net.get_loss<mse>(test_data, test_target_values);
You must specify loss-function by template parameter. We recommend you to use the same loss-function to training.
net.fit<cross_entropy>(...);
net.get_loss<mse>(...); // not recommended
net.get_loss<cross_entropy>(...); // ok :)
visualize the model¶
visualize graph networks¶
We can get graph structure in dot language format.
input_layer in1(shape3d(3,1,1));
input_layer in2(shape3d(3,1,1));
add added(2, 3);
linear_layer linear(3);
relu_layer relu();
(in1, in2) << added << linear << relu;
network<graph> net;
construct_graph(net, { &in1, &in2 }, { &linear } );
// generate graph model in dot language
std::ofstream ofs("graph_net_example.txt");
graph_visualizer viz(net, "graph");
viz.generate(ofs);
Once we get dot language model, we can easily get an image by graphviz:
dot -Tgif graph_net_example.txt -o graph.gif
Then you can get:
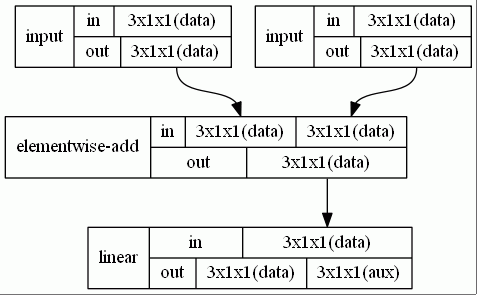
visualize each layer activations¶
network<sequential> nn;
nn << convolutional_layer(32, 32, 5, 3, 6) << tanh()
<< max_pooling_layer(28, 28, 6, 2) << tanh()
<< fully_connected_layer(14 * 14 * 6, 10) << tanh();
...
image img = nn[0]->output_to_image(); // visualize activations of recent input
img.write("layer0.bmp");
visualize convolution kernels¶
network<sequential> nn;
nn << conv(32, 32, 5, 3, 6) << tanh()
<< max_pool(28, 28, 6, 2) << tanh()
<< fc(14 * 14 * 6, 10) << tanh();
...
image img = nn.at<conv>(0).weight_to_image();
img.write("kernel0.bmp");
io¶
save and load the model¶
You can use network::save and network::load to save/load your model:
network<sequential> nn;
nn << convolutional_layer(32, 32, 5, 3, 6) << tanh()
<< max_pooling_layer(28, 28, 6, 2) << tanh()
<< fully_connected_layer(14 * 14 * 6, 10) << tanh();
...
nn.save("my-network");
network<sequential> nn2;
nn2.load("my-network");
The generated binary file will contain:
- the architecture of model
- the weights of the model
You can also select file format, and what you want to save:
// save the weights of the model in binary format
nn.save("my-weights", content_type::weights, file_format::binary);
nn.load("my-weights", content_type::weights, file_format::, file_format::json););
// save the architecture of the model in json format
nn.save("my-architecture", content_type::model, file_format::json);
nn.load("my-architecture", content_type::model, file_format::json);
// save both the architecture and the weights in binary format
// these are equivalent to nn.save("my-network") and nn.load("my-network")
nn.save("my-network", content_type::weights_and_model, file_format::binary);
nn.load("my-network", content_type::weights_and_model, file_format::binary);
If you want the architecture model in string format, you can use to_json and from_json.
std::string json = nn.to_json();
cout << json;
nn.from_json(json);
Note:operator <<andoperator >>APIs before tiny-dnn v0.1.1 are deprecated.
import caffe’s model¶
reading data¶
from MNIST idx format
vector<vec_t> images;
vector<label_t> labels;
parse_mnist_images("train-images.idx3-ubyte", &images, -1.0, 1.0, 2, 2);
parse_mnist_labels("train-labels.idx1-ubyte", &labels);
from cifar-10 binary format
vector<vec_t> images;
vector<label_t> labels;
parse_cifar10("data_batch1.bin", &images, &labels, -1.0, 1.0, 0, 0);
reading images¶
You can use a simple tiny_dnn::image class to handle your images. JPEG (baseline & progressive), PNG (1/2/4/8 bit per channel), BMP (non-1bp, non-RLE), GIF are supported reading formats. Note that it’s memory layout differs from OpenCV - it’s layout is KHW (K:channels, H:height, W:width).
// default underlying type is uint8_t, and memory layout is KHW
// consider following 2x2 RGB image:
//
// R = [R0, R1, G = [G0, G1, B = [B0, B1,
// R2, R3] G2, G3] B2, B3]
//
// memory layout of tiny_dnn::image is KHW, and order of channels K depends on its image_type:
//
// gray_img = { gray(R0,G0,B0), gray(R1,G1,B1), gray(R2,G2,B2), gray(R3,G3,B3) }
// rgb_img = { R0, R1, R2, R3, G0, G1, G2, G3, B0, B1, B2, B3 }
// bgr_img = { B0, B1, B2, B3, G0, G1, G2, G3, R0, R1, R2, R3 }
//
// gray(r,g,b) = 0.300r + 0.586g + 0.113b
image<> gray_img("your-image.bmp", image_type::grayscale);
image<> rgb_img("your-image.bmp", image_type::rgb);
image<> bgr_img("your-image.bmp", image_type::bgr);
// convert into tiny-dnn's interface type
vec_t vec = img.to_vec();
// convert into HWK format with RGB order like:
// { R0, G0, B0, R1, G1, B1, R2, G2, B2, R3, G3, B3 }
std::vector<uint8_t> rgb = rgb_img.to_rgb();
// load data from HWK ordered array
rgb_img.from_rgb(rgb.begin(), rgb.end());
// resize image
image<> resized = resize_image(rgb_img, 256, 256);
// get the mean values (per channel)
image<float_t> mean = mean_image(resized);
// subtract mean values from image
image<float_t> subtracted = subtract_scalar(resized, mean);
// png,bmp are supported as saving types
subtracted.save("subtracted.png");
get/set the properties¶
traverse layers¶
// (1) get layers by operator[]
network<sequential> net;
net << conv(...)
<< fc(...);
layer* conv = net[0];
layer* fully_connected = net[1];
// (2) get layers using range-based for
for (layer* l : net) {
std::cout << l->layer_type() << std::endl;
}
// (3) get layers using at<T> method
// you can get derived class,
// throw nn_error if n-th layer can't be trated as T
conv* conv = net.at<conv>(0);
fc* fully_connected = net.at<fc>(1);
// (4) get layers and edges(tensors) using traverse method
graph_traverse(net[0],
[](const layer& l) { // called for each node
std::cout << l.layer_type() << std::endl;
},
[](const edge& e) { // called for each edge
std::cout << e.vtype() << std::endl;
});
get layer types¶
You can access each layer by operator[] after construction.
...
network<sequential> nn;
nn << convolutional_layer(32, 32, 5, 3, 6) << tanh()
<< max_pooling_layer(28, 28, 6, 2) << tanh()
<< fully_connected_layer(14 * 14 * 6, 10) << tanh();
for (int i = 0; i < nn.depth(); i++) {
cout << "#layer:" << i << "\n";
cout << "layer type:" << nn[i]->layer_type() << "\n";
cout << "input:" << nn[i]->in_data_size() << "(" << nn[i]->in_data_shape() << ")\n";
cout << "output:" << nn[i]->out_data_size() << "(" << nn[i]->out_data_shape() << ")\n";
}
output:
#layer:0
layer type:conv
input:3072([[32x32x3]])
output:4704([[28x28x6]])
num of parameters:456
#layer:1
layer type:max-pool
input:4704([[28x28x6]])
output:1176([[14x14x6]])
num of parameters:0
#layer:2
layer type:fully-connected
input:1176([[1176x1x1]])
output:10([[10x1x1]])
num of parameters:11770
get weight vector¶
std::vector<vec_t*> weights = nn[i]->weights();
Number of elements differs by layer types and settings. For example, in fully-connected layer with bias term, weights[0] represents weight matrix and weights[1] represents bias vector.
change the weight initialization¶
In neural network training, initial value of weight/bias can affect training speed and accuracy. In tiny-dnn, the weight is appropriately scaled by xavier algorithm1 and the bias is filled with 0.
To change initialization method (or weight-filler) and scaling factor, use weight_init() and bias_init() function of network and layer class.
- xavier … automatic scaling using sqrt(scale / (fan-in + fan-out))
- lecun … automatic scaling using scale / sqrt(fan-in)
- constant … fill constant value
int num_units [] = { 100, 400, 100 };
auto nn = make_mlp<tanh>(num_units, num_units + 3);
// change all layers at once
nn.weight_init(weight_init::lecun());
nn.bias_init(weight_init::xavier(2.0));
// change specific layer
nn[0]->weight_init(weight_init::xavier(4.0));
nn[0]->bias_init(weight_init::constant(1.0));
change the seed value¶
You can change the seed value for the random value generator.
set_random_seed(3);
Note: Random value generator is shared among thread.
tune the performance¶
profile¶
timer t; // start the timer
//...
double elapsed_ms = t.elapsed();
t.reset();
change the number of threads while training¶
CNN_TASK_SIZE macro defines the number of threads for parallel training. Change it to smaller value will reduce memory footprint.
This change affects execution time of training the network, but no affects on prediction.
// in config.h
#define CNN_TASK_SIZE 8
handle errors¶
When some error occurs, tiny-dnn doesn’t print any message on stdout. Instead of printf, tiny-dnn throws exception.
This behaviour is suitable when you integrate tiny-dnn into your application (especially embedded systems).
catch application exceptions¶
tiny-dnn may throw one of the following types:
tiny_dnn::nn_errortiny_dnn::not_implemented_errorstd::bad_alloc
not_implemented_error is derived from nn_error, and they have what() method to provide detail message about the error.
try {
network<sequential> nn;
...
} catch (const nn_error& e) {
cout << e.what();
}